国外Link下载中断解决方案—IDM
场景
下载谷歌云的文件,总在没有下载完成的时候就断开了。
不知道出于什么原因。
IDM优势
- IDM似乎不是从头开始下载的,而是直接从文件的不同位置多线程并行开始下载的。
- 说是支持断点续传。
下载链接
https://www.lanzoux.com/b0de8st1e 密码:885w
配置教程
- 下载IDM Chrome拓展
- 选项配置接管
- 关闭IDM,重启浏览器
- 测试是否接管成功
注意
IDM下载速度不一定很快,但是可以保障不断连。
下载谷歌云的文件,总在没有下载完成的时候就断开了。
不知道出于什么原因。
https://www.lanzoux.com/b0de8st1e 密码:885w
IDM下载速度不一定很快,但是可以保障不断连。
A4ONHTMZM2OC7OLRGTGN2XHMTYPCU34FLECK5GB4LNNNNQFEPTAS5Q
是否存在这个问题都不好说,要仔细阅读别人的研究,然后继承和解决。
由于在多目标的DL中只能使用线性加权法,当目标之间的上下界相差较大时,就不得不面对权重的分配问题,这时候均匀的权重分配方案肯定是不合适的,如果存在一个目标的下界比较大,那么加权之后几乎只对较大目标进行优化。
可以直接给较大目标添加一个制定的缩放值,使得上下界相近,来缓解这个问题。
问题是怎么确定这个缩放值,而且解决得也不彻底。
向较大的目标更为细分和多的权重。
也许不存在这个问题?
只要迭代次数够,先将大的目标值下降到不能下降,接下面就是另外一个值的影响了?好像依旧不是很可行。因为梯度分配不能这么做。
目前的一个实验是,记录种群每个目标当前的最大值和最小值,然后将其目标值放缩到0-1。
手动将目标1乘以2提升重要性。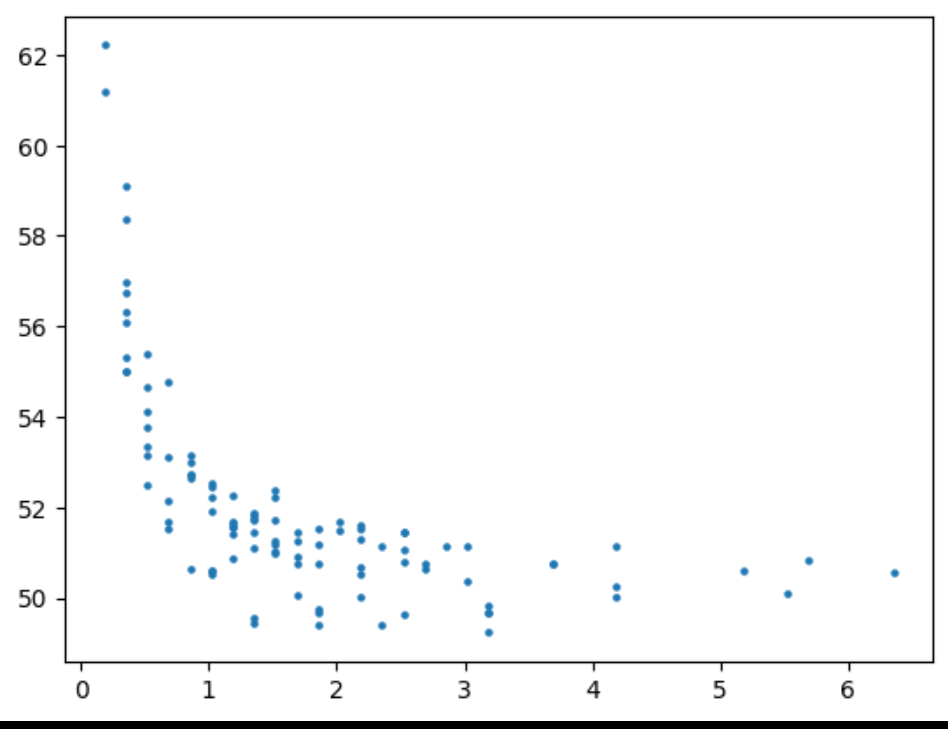
对比不放缩的似乎没什么区别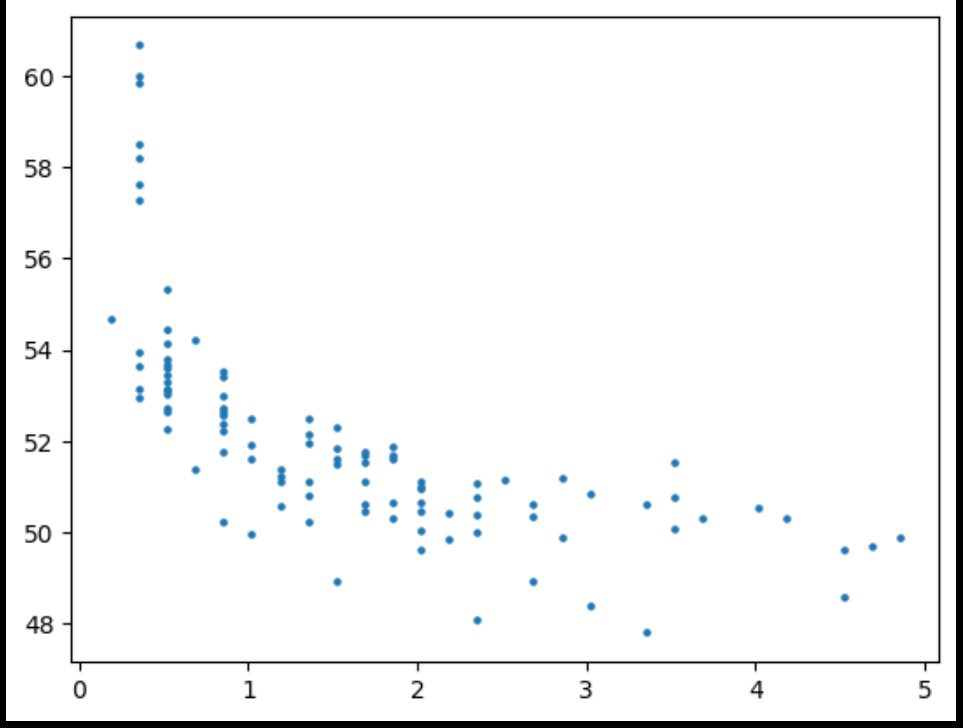

import matplotlib.pyplot as plt
import numpy as np
import random
# 模拟数据
x = list(range(10))
y = [random.randint(0,10) for i in range(len(x))]
y2 = [random.randint(0,10) for i in range(len(x))]
y_upper = y + np.array([random.random() for i in range(len(x))])
y_lower = y - np.array([random.random() for i in range(len(x))])
y_upper2 = y2 + np.array([random.random() for i in range(len(x))])
y_lower2 = y2 - np.array([random.random() for i in range(len(x))])
# 绘制折线图
plt.plot(x, y,color='white')
plt.plot(x, y2,color='white')
plt.fill_between(x, y_lower, y_upper, color="#38C7E8", alpha=1)
plt.fill_between(x, y_lower2, y_upper2, color="#fb8eaa", alpha=1)
# 设置网格线的样式
plt.grid(color='white', linestyle='-', linewidth=1, alpha=0.9)
# 设置网格的背景色
plt.gca().set_facecolor('#e8e8e8') # 灰色底色
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
# 显示图形
plt.show()import matplotlib.pyplot as plt
import numpy as np
import random
# 模拟数据
x = list(range(10))
y = [random.randint(0,5) for i in range(len(x))]
y2 = [random.randint(0,5) for i in range(len(x))]
y_upper = y + np.array([random.random() for i in range(len(x))])
y_lower = y - np.array([random.random() for i in range(len(x))])
y_upper2 = y2 + np.array([random.random() for i in range(len(x))])
y_lower2 = y2 - np.array([random.random() for i in range(len(x))])
# 绘制折线图
plt.plot(x, y,color='#cd676b')
plt.plot(x, y2,color='#5a7fb8')
plt.fill_between(x, y_lower, y_upper, color="#e3c3c9", alpha=1)
plt.fill_between(x, y_lower2, y_upper2, color="#c1cbe1", alpha=1)
# 设置网格线的样式
plt.grid(color='white', linestyle='-', linewidth=1, alpha=0.9)
# 设置网格的背景色
plt.gca().set_facecolor('#ececf3')
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
# 显示图形
plt.show()

好的,让我通过一个简单的例子来说明解码器的生成过程。
假设我们正在进行英语到法语的翻译任务,我们已经训练好了一个 Transformer 模型。现在我们要将一个简单的英文句子 "I love playing basketball." 翻译成法语。
准备工作:
编码器(Encoder):
解码器(Decoder):
生成第一个单词:
生成后续单词:
重复生成过程:
生成结束标记:
通过这个过程,解码器逐词地生成了目标语言的句子,同时考虑了前面已经生成的部分序列和编码器的输出,从而实现了翻译任务。
考虑TSP的翻译,应该是用现有路径去预测下一步,而不是现有节点。
可以先用监督训练看看效果。